Research Interests.
My research interests lie at the intersection of Deep Learning, Computer Vision, 3D Geometry and their applications in Augmented Reality and Robotics. I enjoy studying how deep learning can be applied to computer vision problems including keypoint detection, image matching, relocalization, multi-view reconstruction, visual SLAM, depth estimation, homography estimation, camera calibration and bundle-adjustment.
Bio.
Currently a researcher at Facebook Reality Labs Research (FRL Research). Previously I was a member of the AI Research Team at
Magic Leap I worked on developing new deep learning-based methods for Visual Simultaneous Localization and Mapping (Visual SLAM) and Structure-from-Motion (SfM). I was co-advised by
Tomasz Malisiewicz and
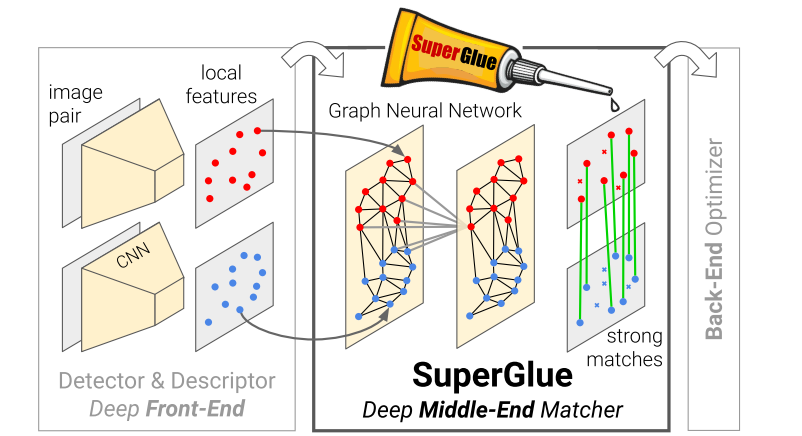
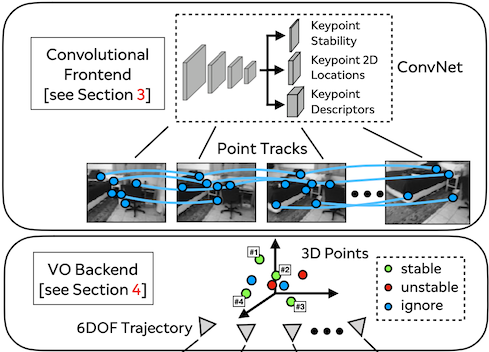
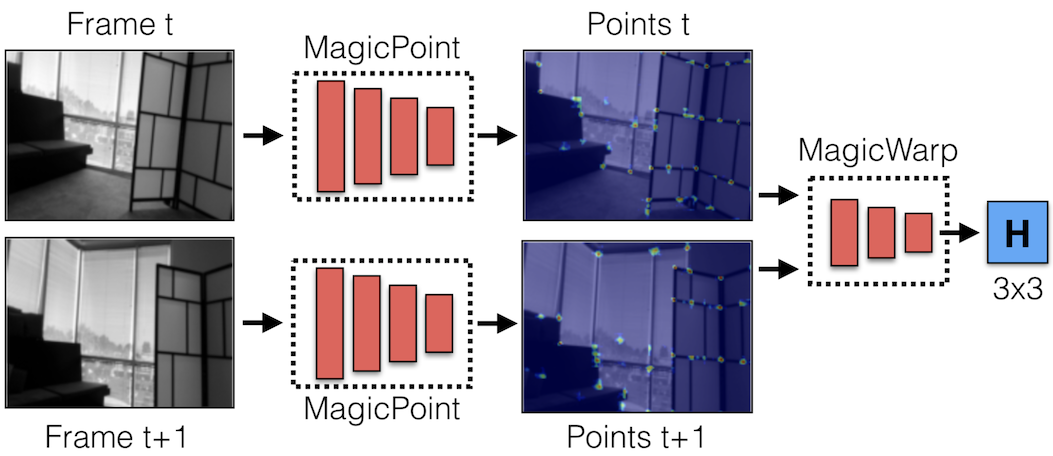
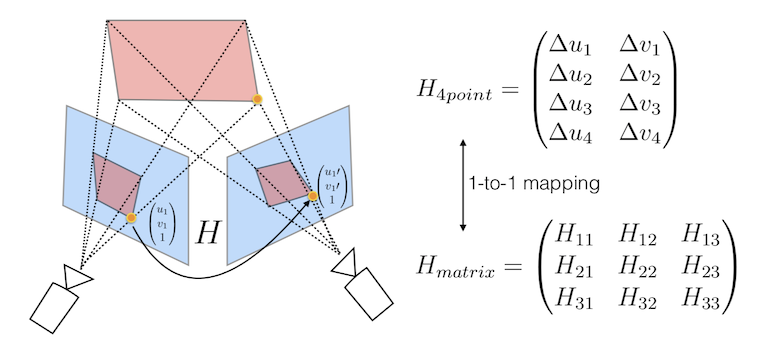
Andrew Rabinovich and authored publications at top-tier conferences including CVPR and RSS (e.g. Deep Homography Estimation, SuperPoint and SuperGlue). I also pioneered computer vision algorithms which were ultimately deployed on the ML1 headset.
Prior to Magic Leap, I received my Master's and Bachelor's degrees at the University of Michigan, where I studied Machine Learning, Computer Vision and Robotics. During my studies I worked on various small projects in areas such as person tracking, outdoor SLAM and 3D ConvNets.
Timeline.
2020-now:
Research Scientist at Facebook
Deep Learning, 3D Mapping
2015-2020:
Lead Software Engineer at Magic Leap
Deep Learning, Visual SLAM, Mixed Reality
2014:
Occipital Internship
RGB-D SLAM, Augmented Reality
2013-2015:
University of Michigan Master's Student
Computer Vision, Machine Learning, Robotics
2008-2013:
University of Michigan Bachelors's Student
Robotics, Computer Science, International Studies
News.
April 2020: Published
PyTorch code for SuperGlue, includes live demo and easy-to-use evaluation code.
March 2020: SuperGlue: Learning Feature Matching with Graph Neural Networks is accepted to CVPR 2020 as an Oral.
March 2019: Deep ChArUco: Dark ChArUco Marker Pose Estimation is accepted to CVPR 2019.
November 2018: Invited talk at Berkeley Artificial Intelligence Research Lab
(BAIR).
October 2018: Invited
Keynote Talk at the Bay Area Multimedia Forum Keynote (BAMMF) series in Palo Alto, CA.
July 2018: Presented SuperPoint at
ICVSS 2018 in stunning Sicily.
June 2018: Published
PyTorch code for SuperPoint. Get up and running in 5 minutes or your money back!
April 2018: SuperPoint selected as an
oral at the
1st International Workshop on Deep Learning for Visual SLAM at CVPR in Salt Lake City.